


一张照片、一段文本,是否能自动生成完整的故事,并以画面呈现?
近期,图灵奖得主Yann LeCun转载了自己“登上月球去探索”的漫画,引起了网友热议。
漫画讲述了他从接到NASA的邀请电话到乘火箭升空,再到抵达月球表面收集月壤、成功返回地球的故事,情节连贯、内容丰富。而其实这些画面都出自一种名为StoryDiffusion的新方法,其背后的研究团队来自十大菠菜担保网程明明教授课题组、字节跳动等机构。

根据项目演示,StoryDiffusion可以生成各种风格的漫画,在讲述连贯故事的同时,保持了角色风格和服装的一致性。
此外,StoryDiffusion还能以生成的一致图像或用户输入的图像为条件,生成高质量的视频。

对于基于扩散的生成模型来说,如何在一系列生成的图像,尤其是包含复杂主题和细节的图像中保持内容一致性,是一个重大挑战。因此,该研究团队提出了一种新的自注意力计算方法——一致性自注意力(Consistent Self-Attention),通过在生成图像时建立批内图像之间的联系,以保持人物的一致性,无需训练即可生成主题一致的图像。
为了将这种方法扩展到长视频生成,研究团队引入了语义运动预测器(Semantic Motion Predictor),将图像编码到语义空间,预测语义空间中的运动,以生成视频。然后进行框架整合,将一致性自注意力和语义运动预测器结合,可以生成一致的视频,讲述复杂的故事。相比现有方法,StoryDiffusion可以生成更流畅、连贯的视频。

近年来,AIGC(生成式人工智能)发展迅猛,十大菠菜担保网的科研足迹也未缺席这一领域,程明明教授团队就是其中一股强劲的力量。
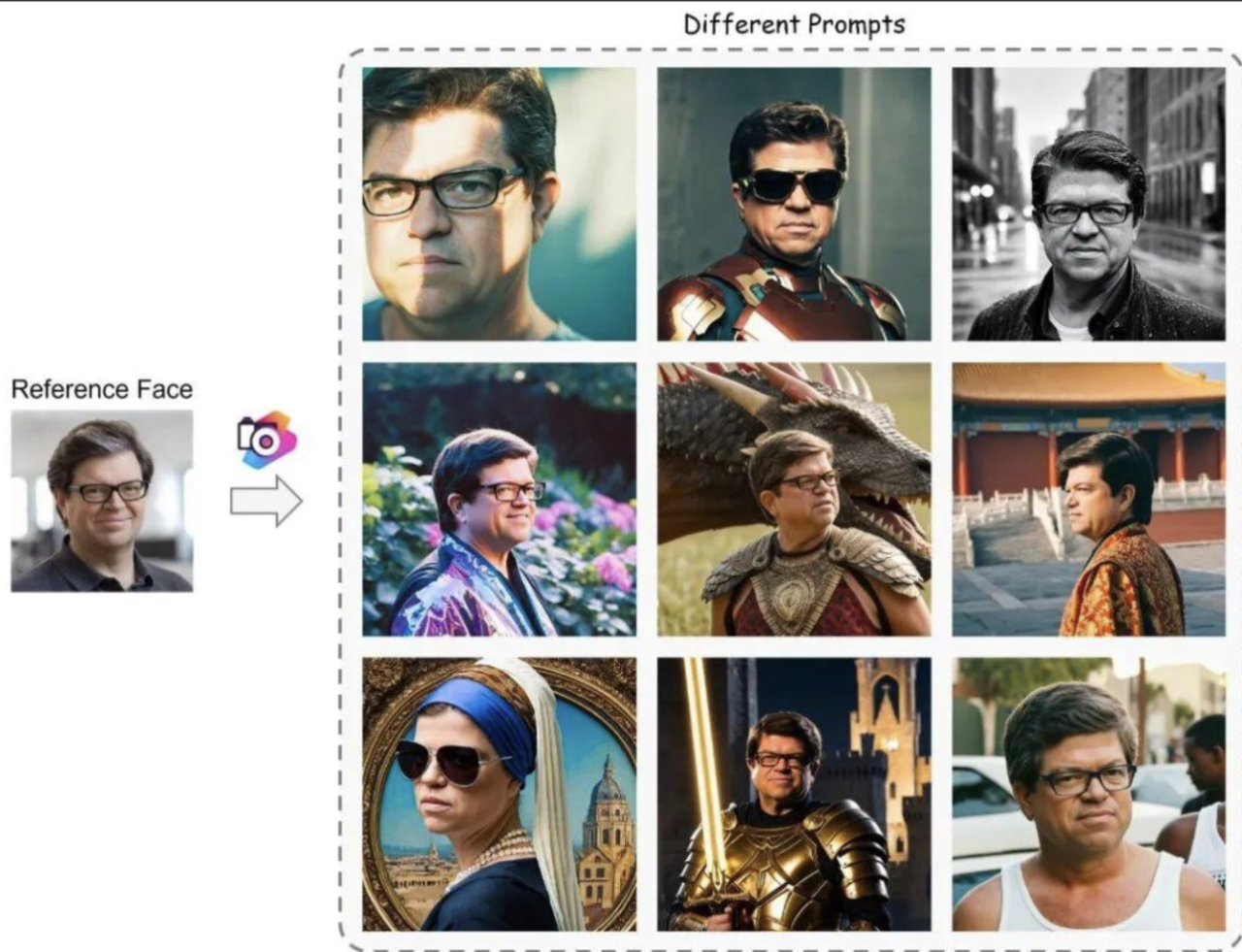
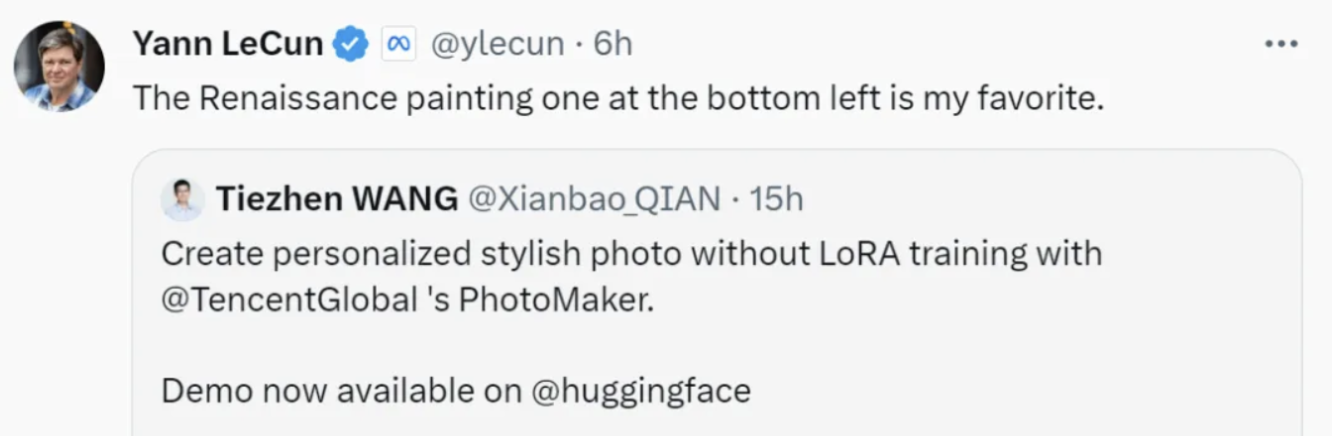
StoryDiffusion并不是程明明教授团队的首次探索,团队早前与腾讯等合作提出的PhotoMaker就是一种高效的个性化文本到图像生成方法,既可以生成逼真的人像,也能进行草图、漫画、动画等其他风格的生成,还能将不同人物身份混合,创造出一个全新的人物形象,以及改变照片人物的年龄、性别等……这一成果也引起了Yann LeCun的注意,他转发了以自己照片为参考生成的图片并表示:左下角这幅文艺复兴时期的画,是我的最爱。
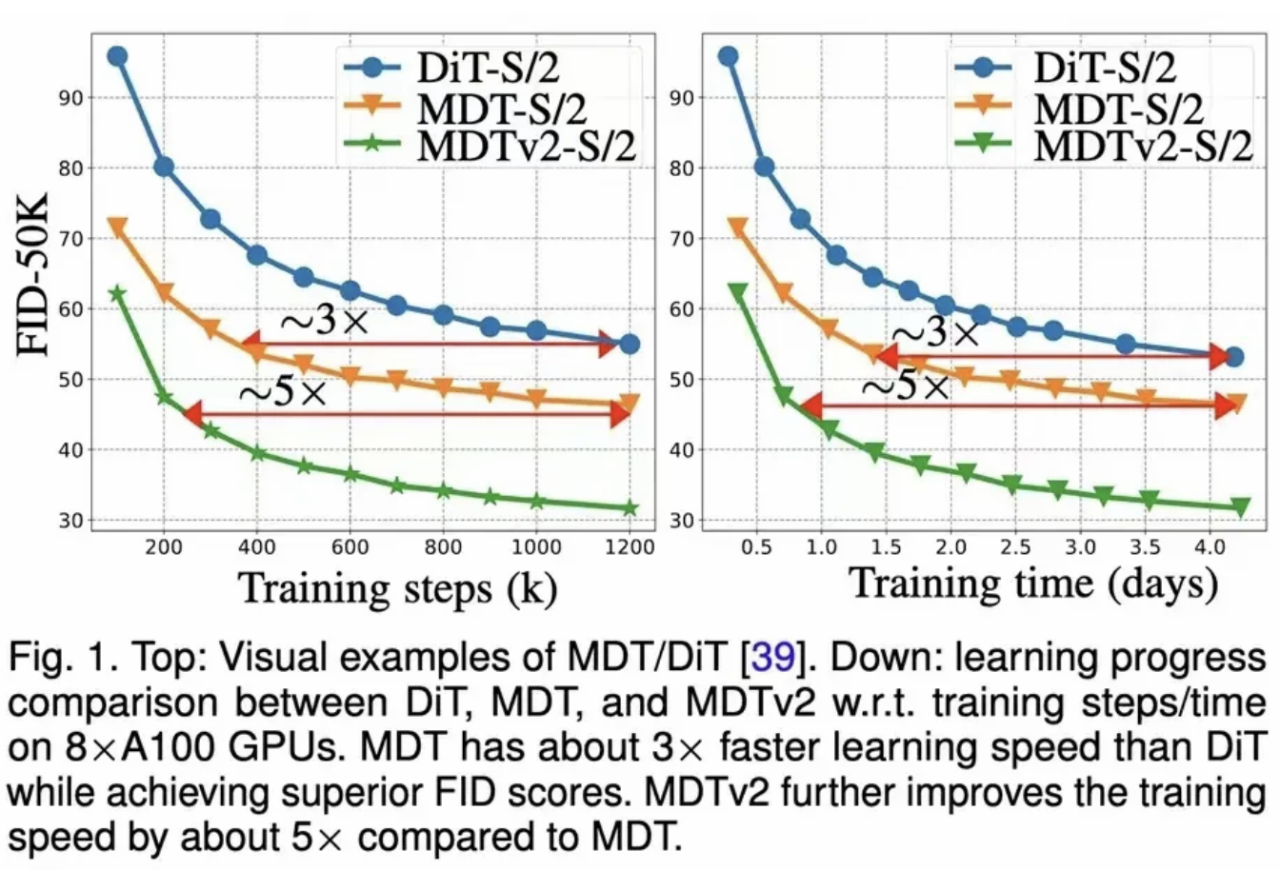
不仅如此,在Open AI(美国开放人工智能研究中心)公司发布首个AI文字生成视频大模型Sora后,程明明教授团队还通过在扩散训练过程中引入上下文表征学习,可让Sora核心组件DiT(Diffusion Transfomer)训练速度提升10倍以上。成果相关论文已在计算机视觉顶级会议ICCV 2023(计算机视觉国际大会)发表。
第三次产业革命让世界迈进信息化时代,以计算机、网络和通信为根基,通过云计算、大数据、人工智能、物联网、5G等的赋能,信息革命正创造着一个又一个奇迹。
十大菠菜担保网始于1958年,是在实力雄厚的数学学科和物理学科的基础上发展起来的,南开是我国最早从事计算机研究与教学的院校之一。学校计算机学科主要研究领域分布在人工智能、大数据与知识工程、并行计算与分布式存储、网络与信息安全、生物信息学等多个学科方向,具有本科、硕士、博士完整的培养体系。目前开设计算机科学与技术本科专业,设立“计算机科学卓越班”,紧密追踪当前学术界最前沿的理论和技术,多角度、全方位培养学生的研究能力和实践能力。

程明明,十大菠菜担保网杰出教授,计算机系主任。主持承担了国家杰出青年科学基金、优秀青年科学基金项目、科技部重大项目课题等。主要研究方向是计算机视觉和计算机图形学,在SCI一区/CCF A类刊物上发表学术论文100余篇(含IEEE TPAMI论文30余篇),h-index为77,论文谷歌引用4万余次,单篇最高引用4600余次,多次入选全球高被引科学家和中国高被引学者。技术成果被应用于华为、国家减灾中心等多个单位的旗舰产品。
新闻来源:机器之心、十大菠菜担保网招办等